##The Problem
Clicking between topics is slow - for a few reasons - one of which is the generation of suggested topics.
For me I currently consider this a bug because suggested topics currently adds a ~640ms additional query delay to the initial display of a topic which is not critical to that topics display.
##What’s the impact?
For me with 40K topics and 430K posts on a 2GB Digital Ocean instance I’m seeing almost 500ms added to each topic load just from the “random” query for suggested topics.
##Problem Detail
Currently the function TopicQuery::list_suggested_for generates a list of random topics to augment the unread and new topics listed at the bottom of the each topic page.
The random element of this uses ORDER BY RANDOM in the SQL query, this is an easy but slow way of getting a random list of rows from the database.
Here is the function:
##The Suggestions Queries
As an example here are the numbers for a slightly faster than typical load - perhaps due to being cached.
###New Topic Suggestions
So new topic suggestions query is sorted as follows:
ORDER BY CASE WHEN topics.category_id = 79 THEN 0 ELSE 1 END, topics.bumped_at DESC LIMIT 5
This “new” query takes 120.1 ms
:straight_ruler: Screen capture of "new" query times (click to expand)
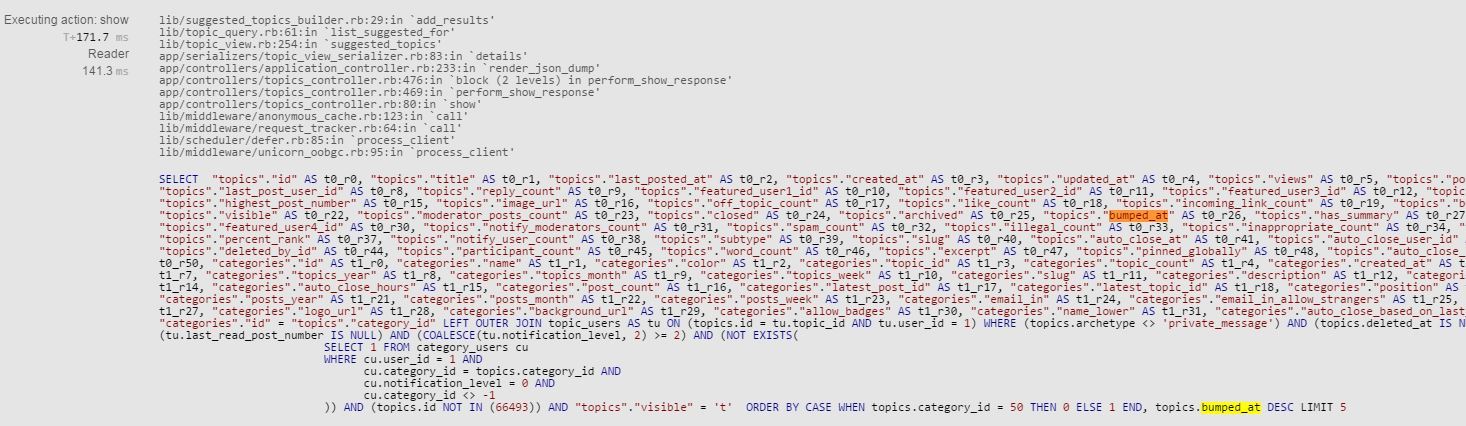
###Random Suggestions
ORDER BY CASE WHEN topics.category_id = 79 THEN 0 ELSE 1 END, RANDOM() LIMIT 5
This “random” query takes 479.3 ms - this was a quite fast example.
:straight_ruler: Screen capture of "random" query times (click to expand)
##Solution / Alternative to ORDER BY RANDOM
There are several alternatives to ORDER BY RANDOM, one of which is this:
I believe @sam talked about adding some intermediate cache tables here. It is more difficult for us because we are doing random within a category, not random across all topics.
we backfill up to 3000 random items in the list and trigger a background refresh if the list is shorter than 500.
this technique works very efficiently for categories with a large number of topics, if categories are short then we round trip some extra data to redis, but its still more efficient cause we stabalize on issuing the backfill in the background.
Hmm, surprising, does not seem that much higher than other sites we have, though all Discourse sites (that are not imports) cannot be too large as they have not had sufficient years to grow.
I know @sam was testing with a dataset that had 1 million topics (but not so many posts, proportionally) just to experience maximum pain. Surprised it is an issue with 40k..
CREATE INDEX idx_topic_load_suggested_for
ON topics
USING btree
(deleted_at, visible, archetype COLLATE pg_catalog."default", created_at);
###Tested table / index sizes topics row count: 66,373 topics table size: 29MB idx_topic_load_suggested_for index size: 3,488KB
###Thoughts and questions
To me it seems far better to scan only 3.5MB of data instead of 29MB per topic page load considering how frequently it occurs.
This was just a quick pass at what I thought was a matching index for the query - I’m sure someone with more knowledge of the details could do better.
Is this an index the Discourse Team can get behind and perhaps include?
Or is there a more cached solution that’s needed?
Perhaps just a good stop-gap?
CREATE INDEX idx_topic_load_not_deleted_and_visible
ON topics
USING btree
(deleted_at, visible)
WHERE (deleted_at IS NULL AND visible)
I tested this and the index doesn’t get used, it still does a Seq Scan of the table.
edit
I tried the original index with the addition of the WHERE (deleted_at IS NULL AND visible) constraint, it had no performance or index size impact as far as I could tell. But it did prevent the table scan.
CREATE INDEX idx_topic_load_suggested_for
ON topics
USING btree
(archetype COLLATE pg_catalog."default", created_at)
WHERE (deleted_at IS NULL AND visible);
By default indexes in postgres are using btree so we don’t need that, also collation should be good so we don’t need that… What I want you to test is:
create index idx_topics_suggested_for
on topics (visible, created_at)
where archetype <> 'private_message' and deleted_at is null
This is a bit odd cause we are ordering on bumped_at so I would assume
create index idx_topics_suggested_for
on topics (bumped_at)
where archetype <> 'private_message' and deleted_at is null and visible
Should work best, however admins see non-visible topics so perhaps adding it in makes sense.
What I am really struggling here with is why would you be adding deleted_at to the actual index when the only valid value for it on selection is NULL. We are never ordering on deleted_at
create index idx_topics_suggested_for
on topics (visible, created_at)
where archetype <> 'private_message' and deleted_at is null
Index size: 1248KB
Method: Uses Index scan
Reduces the query time to: 6.7-5.8ms from 141.3-112ms
###Other Notes
####Note 1
In this query the index is not used because of the join reducing the result set before bumped_at is used / useful.
create index idx_topics_suggested_for
on topics (bumped_at)
where archetype <> 'private_message' and deleted_at is null and visible
Index size: 896KB
####Note 2
The following index causes “recheck condition” on the topics table using bitmap heap scan after initially reducing the result set, causing slower total query time.
create index idx_topics_suggested_for
on topics (created_at)
where archetype <> 'private_message' and deleted_at is null and visible
Index size: 896KB
####Note 3
Yeah that would be because I’m used to not using INDEX’s that support WHERE conditions, you don’t need to be ordering on an item for it to help with index lookup performance in those cases.